

EP-78|Claude Fable 5 雖然很強,但是它的價格更是驚人
6 月 22 日後訂閱戶得另外儲值才能用 Fable 5。拆解它的真實定位,以及怎麼用三層 Subagent 依任務派模型、省下昂貴額度。


補充說明:這篇文章是在禮拜四晚上寫的。結果隔天,Fable / Mythos 5 就受到美國官方下令禁止非美國地區使用。原因當然是跟國家安全有關係。這也意味著,各國都應該要加強開發屬於自己的 AI,避免受制於其他國家。
—
如果你有在使用 Claude Code 或是 Claude 桌面版的話,在上個禮拜你應該有看到更新。更新完之後,你就會發現有一個新的模型叫做 Fable 5。
它是最新的旗艦模型。
在 6 月 22 日以前,只要你有訂閱,不管是哪一個層級的 Pro、Max 或者企業版,你就可以使用 Fable。
在這之後,Anthropic 就會把它從訂閱方案中移除,繼續使用需要消耗 usage credits,意思就是要多收錢啦。不是說你有訂閱就可以爽用,你有訂閱也不會給你用,要用的話要另外儲值。
費率是 API 價格:輸入 $10/百萬 token、輸出 $50/百萬 token,是 Opus 4.8 的兩倍。貴到嚇死人。
當然,這麼貴的價格代表它有強大的能力。
Fable 5 其實就是之前吵得沸沸揚揚的的 Mythos,據說能力非常強大,能夠自己抓到資安漏洞的大型語言模型。
由於 Mythos 的能力實在是太強了,所以 Anthropic 特別為了 Fable 5 多加了一層護欄。提供給一般使用者。另外還有一個 Mythos 5 ,安全限制較少,提供企業使用。
我自己單純是覺得,也許是因為 ChatGPT 5.5 太強了,而 Claude Opus 4.8 表現起來,又差強人意,所以迫於壓力的 Anthropic 不得不推出一個新的旗艦模型。
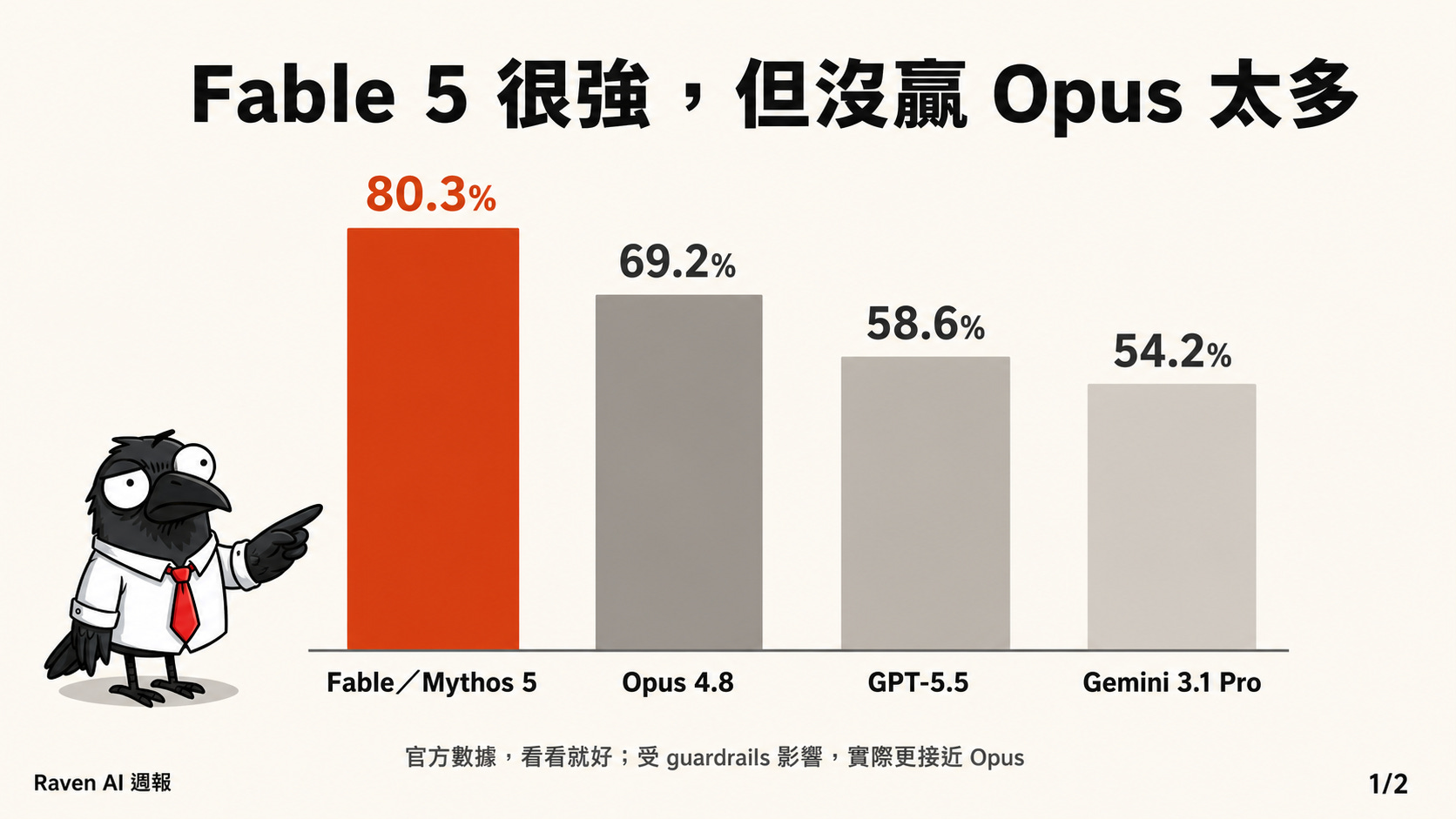
Claude Fable 5 雖然很強,但是也不會贏過 Opus 太多
Anthropic 在 2026 年 6 月 9 日發布 Claude Fable 5。
根據 Anthropic 的說法是,Fable 5 主打長時間的 AI 代理工作、程式開發、知識工作與視覺理解。
從一些官方文件以及一些英文媒體的資料來看,Fable 5 可以說就是一個 Mythos 的閹割版,針對資安、生物與生命科學等高風險能力,額外加了安全分類器。
當 Fable 判定某個請求碰到這些高風險區,會自動把問題改交給 Opus 4.8 回答。
目前 Fable 在 Benchmark 的表現上,官方資料顯示都贏過 ChatGPT 5.5 。以程式任務的 SWE-Bench Pro 為例,Fable 5 /Mythos 5 拿到 80.3%,高於 Opus 4.8 的 69.2%、GPT-5.5 的 58.6% 與 Gemini 3.1 Pro 的 54.2%。
可是,因為 Fable 5 有安全分類器,所以上述的 Benchmark 成績,其實應該是 Mythos 5 的成績。Fable 5 我覺得就只能把它視為是 Opus +。在資安與生物等受 guardrails 影響較大的指標上,正式對外的 Fable 5 可能更接近 Opus 4.8 的實際表現。
總之呢,Benchmark 成績,看看就好。
因為這一兩年來,反正 ChatGPT 推出新模型之後就說它的模型最強,那這個 Claude 推出來之後呢,也說它的模型最強。
目前最強閉源模型都是 Claude 跟 ChatGPT 在互相競爭,Gemini 目前已經落後了,Grok 則是不知道在幹嘛,希望他們能加把勁。

Fable 5 的額度消耗量實在太大了,建議設定 Subagent
最近這幾天我都有用 Fable 5。
Fable 5 的確是比較強,可是大約每十次使用,可能就會有一次觸發它的安全分類器。
我的工作其實也不太會故意去挑戰一些違反資安的工作,平常主要是讓 AI 去讀系統裡的 log,然後幫我分析目前的問題。
但是光是這樣子使用的時候,它有時候會撞到護欄,然後直接把問題丟給 Opus 4.8 讓它去回答。
雖然我看了一些網路資料,據說如果撞到護欄,在它還沒有把文字產出的時候,所消耗的 token 不會計算到我們的額度裡面,但還是很浪費時間。
還有在體感上,使用 Fable 5額度消耗得特別快。
我平常都是用 Opus 4.8,每天就是讓它讀一下 log 的資料,不然就是寫 GAS 腳本做自動化,很少撞到上限。
改用 Fable 5 之後大概用個幾次,我的額度就滿了。我還是 100 美金的 Max 使用者咧。
就是因為這樣,所以我後來就決定要設定使用子代理(Subagent)來節省一下我的使用量。
設定方式也很簡單,你就是跟 AI 說,你希望在你的本地端能夠依照任務去設定子代理,依照不同的任務呼叫不同的模型。它就會幫你設定了。
目前我設定了三層模型:
第一層:Sonnet 是預設值,所有沒有觸發升級條件的任務都在這裡處理。
第二層:Opus ,當 Sonnet 判斷任務步驟超過五步、需要同時整合多個來源的資訊、或者任務性質屬於架構設計、深度研究,它就會呼叫 Opus Sub-agent。Opus 的強項是長程自主推理,能夠自己規劃完整的解題路徑,再一步一步執行完畢。
第三層:Fable 是我幾乎不主動觸發的選項,因為也只有最近才能用,6月23日開始都是要儲值才能用。如果要等到 Anthropic 開放一般訂閱戶也能使用 Fable,不知道要等到猴年馬月。
但是如果未來它有開放的話,可以預測消耗的額度應該也很可觀,除非 Opus 跑起來不夠理想,AI 此時就可以給我建議,讓我自己決定要不要使用 Fable。
原則上就是讓 AI 自己根據任務的難度,決定「這件事該派誰去做」,而不是每次都動用最貴的資源。
CTA
如果你跟我一樣,每次有新模型出來都想自己搞清楚它能不能放進工作流,不想只跟著英文媒體的情緒走,那我們社群會很適合你。我固定會在社畜進化論裡跟大家拆各種最新 AI 技術以及如何套用在工作流。想跟著第一線討論一起練判斷力的話,我們這裡見: