

【EP-28】 踩著 AI 的肩膀,成為更好的人類:介紹 Felo Agent 與 n8n 自動化抓取 Notion 筆記
我最近都在想採用更好的方法製作專屬的第二大腦,雷蒙三十建議可以用 Felo AI ,我測試過了,真的很棒,可惜無法讀取 Notion 筆記。於是我用 n8n 自動化抓出 Notion 資料庫內所有文章,改用 Windsurf 去編輯,效果也很讚!

在上一期電子報,我提及了第二大腦的想法。
簡單來說,我認為第二大腦不只是結構化的數位筆記方法,而是運用閱讀了大量公開資料的大型語言模型,以此為基底,結合數位筆記,才是真正的第二大腦。
問題是,該怎麼結合?
在 EP-27 電子報,我示範了 ChatGPT Plus 的自訂GPT,結合 n8n 自動化,串連 Notion 個人筆記。
但是我並不是把整個 Notion 筆記做成向量資料庫,而是搜尋單篇筆記資料,再讓 ChatGPT 閱讀。
這樣的成果,對我來說是不夠滿意的。
今天要介紹更好用的方式。
Felo AI
可能很多人都聽過 Perplexity 了,一款結合大型語言模型的搜尋引擎。
Felo AI 也是同樣的產品,免費版一天可以使用 5 次專業搜尋,用完就換 Perplexity 的免費額度,快樂地當個免費仔。
要如何將 Felo AI 連到你的網站,開啟一個專屬於你個人網站的聊天機器人呢?方法也很簡單。
登入 Felo AI ,點擊左側的 Felo Agent ,然後再點擊「建立」,就可以開始編輯了。
只要在「自定義提示詞」這裡,說明你指定要它搜尋的網站即可。
這是我設定的聊天機器人,有需要可以測試看看。
Felo AI 的自定義 Agent ,看起來很像是 ChatGPT 的自訂 GPT ,但是功能要強多了。
我按照同樣的方式操作 ChatGPT ,完全沒辦法讓它只搜尋特定網站的資料。
但是,Felo AI 也不是完全沒缺點。
目前 Felo AI 只能搜尋標準網頁結構的資料(這是我的猜測),因為我將 Notion 資料庫公開,例如我的學習筆記。
Felo AI 爬我的 Notion 筆記沒這麼順利,我測試了多個連結都不行。
可是我們的訴求是將 AI 連結我們的個人筆記,雖然 Felo AI 能夠閱讀我的電子報,但是電子報內容已經是我經過深思熟慮寫出來內容,本來就是可以公開的。
我更希望的是讓 AI 去閱讀一些我還在學習的筆記內容,以及我一些不成熟還不太適合公開的想法。
使用 n8n 取出 Notion 資料庫的所有資料
Notion 雖然好用,但是資料庫的邏輯很特別,所以沒辦法丟給 ChatGPT 或 Felo AI 去讀取。
因此如果你的資料庫很多文章,假設要一篇一篇複製貼到 Word ,然後丟給語言模型處理,你會弄到起笑。
最好的方法是用 n8n 自動化工具來抓。
抓完之後,隨便你想怎麼處理都可以,像我最近就想採用 Windsurf + Obsidian ,在本地端編輯文章,然後讓 AI 提供編輯意見。
要設定必須要搞定 Notion 與 n8n 的連接,可以閱讀我的 EP-12 電子報。
底下是我設定的流程:
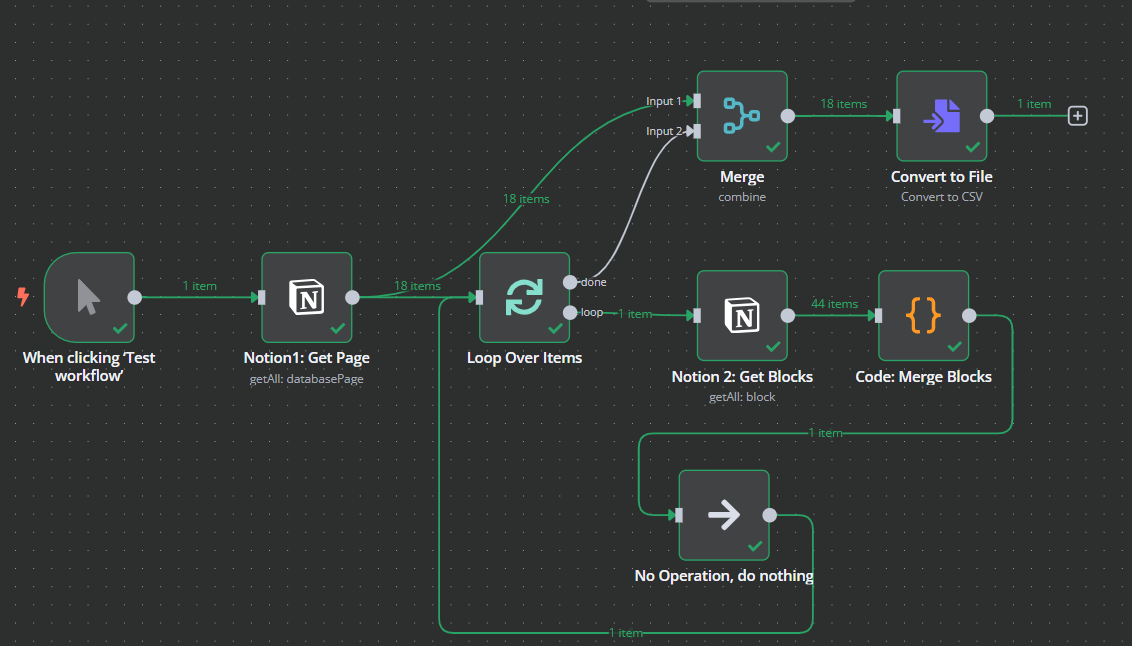
1. 取得 Notion 資料庫所有頁面
Notion 節點設定:Resource 選擇 Database Page ,Operation 選擇 Get Many ,Database 就選擇指定的資料庫,如果你一開始就串接好了,這時就會看得到資料庫名稱。
2. 分別進入每一篇文章標題內抓資料
除非你跟一般人不同,否則使用 Notion 資料庫寫文章時,通常會把標題那邊當作文章置放的地方。因此你抓取 Notion 資料庫,第一層只能抓到所有文章 id 與名稱。
你需要一個迴圈節點。
Loop 節點設定:Batch Size 填1 ,意思是一次只處理一筆資料,然後進入下一輪 loop 再處理下一筆。
3. Loop 節點後的 loop 端口接 Notion 節點處理文章
Notion 文章是由許多 Blocks 組成的,反正是他們的術語,這裡不用管。
總之 Loop 節點會有兩個端口,一個是 loop ,另一個是 done 。
loop 端口要接 Notion 節點,負責抓出所有 Blocks 。
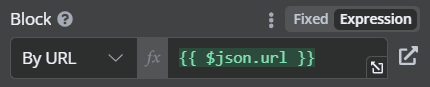
Notion 節點設定:Resource 選擇 Block ,Operation 選擇 Get Child Blocks ,Block 選擇 By url,指定上一層的 url
4. 合併所有 Blocks
上面說了,一個文章可能有數十個數百個 Blocks ,這些都很分散,現在我們要把所有 Blocks 合併在一起,才是一篇文章。
所以這裡寫個小程式作這件事:
return [
{
json: {
page_id: $json.parent.page_id, // Notion block 裡的原始 page ID
content: $items().map(item => item.json.content).filter(Boolean).join('\n')
}
}
];
5. 處理文章的 Notion 節點,後面要接一個 No Operation 節點
這部分是我問 ChatGPT 的,執行迴圈時,要把工作流拉回來原來的 loop 節點。
如果沒有 No Operation 節點,可能會因為資料結構不同或節點尚在處理中導致流程錯誤或中斷。
6. Loop 節點後的 done 端口,接 Merge 節點
現在我們有合併後的文章及各文章的 id ,然後一開始我們就抓了所有文章標題與 id 。
這邊當然要再一次合併起來啊!
Merge 節點預設有兩個入口,Input 1 接第一個 Notion 節點, Input 2 接Loop 節點後的 done 端口,反過來也行,沒差。
Merge 節點設定:Mode 選擇 Combine,Comebine by 選項,選擇 Matching Fields 。
底下的 Fields To Match Have Different Names 要打開,然後把指定要配對的 id 丟進去,如下圖。

7. 產出 CSV 檔下載
最後當然就是要下載啊,這裡我選擇下載 CSV 檔。
Convert to file 節點設定:Operation 選擇 Convert to CSV ,File Name 隨便你取名。
8. 採用 AI 讀取大量文章
最後就是下載所有資料庫的檔案,看你要丟到 NotebookLM ,還是使用 Windsurf 或 Cursor 結合 Obsidian 編輯都可以。
現在,第二大腦終於完成了,之後我會寫一篇文章,討論實際上如何應用第二大腦。
我這邊文章寫得好辛苦,給我一顆愛心好嗎?
或者,如果真的對您有幫助,也歡迎贊助我。